AI servers are no longer only a GPU story. The latest generation of AI infrastructure is changing the role of memory inside the data center. High Bandwidth Memory (HBM), DDR5 server memory, CXL memory expansion, advanced packaging and AI-optimized storage are now shaping system cost, platform performance and supply-chain risk.
This shift is visible in both technical specifications and cost structure. NVIDIA H200 increased GPU memory to 141GB of HBM3E with 4.8TB/s bandwidth, while Blackwell Ultra GB300 raises per-GPU memory capacity to 288GB of HBM3E for larger reasoning and long-context inference workloads (NVIDIA H200 Product Information; NVIDIA GB300 NVL72 Product Information). AMD is following the same direction, with MI300X offering 192GB of HBM3 and MI325X increasing to 256GB of HBM3E with 6TB/s bandwidth (AMD Instinct MI300 Series).
At the rack level, the economics are even more telling. Based on third-party BOM estimates used in this article, GPU cost rises by about 57% from a GB300 NVL72-class rack to a VR200 NVL72-class rack, while memory cost rises by about 435%. Memory is not simply following GPU growth. It is becoming one of the fastest-growing value centers in AI server architecture.
AI Server Shipments Keep Expanding
The growth of AI servers does not look like a short procurement spike. TrendForce estimated that global AI server shipments would grow more than 20% in 2026, with AI servers reaching about 17% of total server shipments. A later TrendForce update projected AI server shipments to grow more than 28% year over year in 2026, supported by North American cloud service providers, sovereign cloud projects, inference workloads and custom AI ASIC deployment (TrendForce AI Server Forecast).
The shipment data compiled for this article points in the same direction. AI server shipments increased from roughly 1.2 million units in 2023 to about 1.75 million units in 2024, then moved toward approximately 2.17 million to 2.20 million units in 2025. The 2026 estimate moves toward 2.65 million to 2.70 million units, with 2027 potentially exceeding 3.2 million units.
| Year | AI Server Shipments | YoY Growth | AI Server Share of Server Market | Main Driver |
|---|---|---|---|---|
| 2023 | ~1.2 million units | +38.4% | ~9% | Early large-scale AI server deployment |
| 2024 | ~1.75 million units | +46% | ~12.1% | H100 / H200 platform ramp |
| 2025 | ~2.17–2.20 million units | +24.3% | ~14% | GB200 and GB300 deployment |
| 2026 | ~2.65–2.70 million units | >20% | ~17% | GB300, Rubin and AI ASIC systems |
| 2027 | 3.20 million+ units | ~20% estimated | ~20% estimated | Inference expansion and sovereign AI infrastructure |

The important point is not only shipment growth. AI servers use much more memory per system than traditional servers. The data set used for this article estimates that AI servers may use roughly 8 times more DRAM and 3 times more NAND flash than traditional servers, while also adding hundreds of gigabytes to terabytes of HBM capacity depending on GPU count. That demand reaches far beyond one memory category.
The BOM Shift: Memory Becomes a Cost Center
The most direct evidence of the memory shift comes from AI server BOM structure. In a conventional server, CPUs, DRAM, storage, power, cooling and networking share cost more evenly. In an AI server rack, GPUs still dominate the headline cost, but memory is becoming one of the fastest-growing incremental components.
Based on the BOM comparison data used in this report, total BOM cost rises from about $3.99 million for GB300 NVL72 to about $7.80 million for VR200 NVL72, an increase of about 95%. GPU cost rises from roughly $2.52 million to $3.96 million, or about 57%. Memory cost, however, rises from about $373,939 to about $2.00 million, an increase of roughly 435%.
| Component | GB300 NVL72 Estimate | VR200 NVL72 Estimate | Growth |
|---|---|---|---|
| GPU | $2.52M | $3.96M | +57% |
| Memory | $373,939 | $2,001,600 | +435% |
| NVLink Switch | $64,800 | $144,000 | +122% |
| PCB | $35,100 | $116,730 | +233% |
| Total BOM | $3.99M | $7.80M | +95% |


This does not mean memory becomes more expensive than the GPU complex. It means the cost structure of AI racks is changing. Incremental value is moving toward HBM, modular memory, memory interfaces, advanced PCBs, power delivery and high-density packaging.
GPU Platforms Are Now Memory Platforms
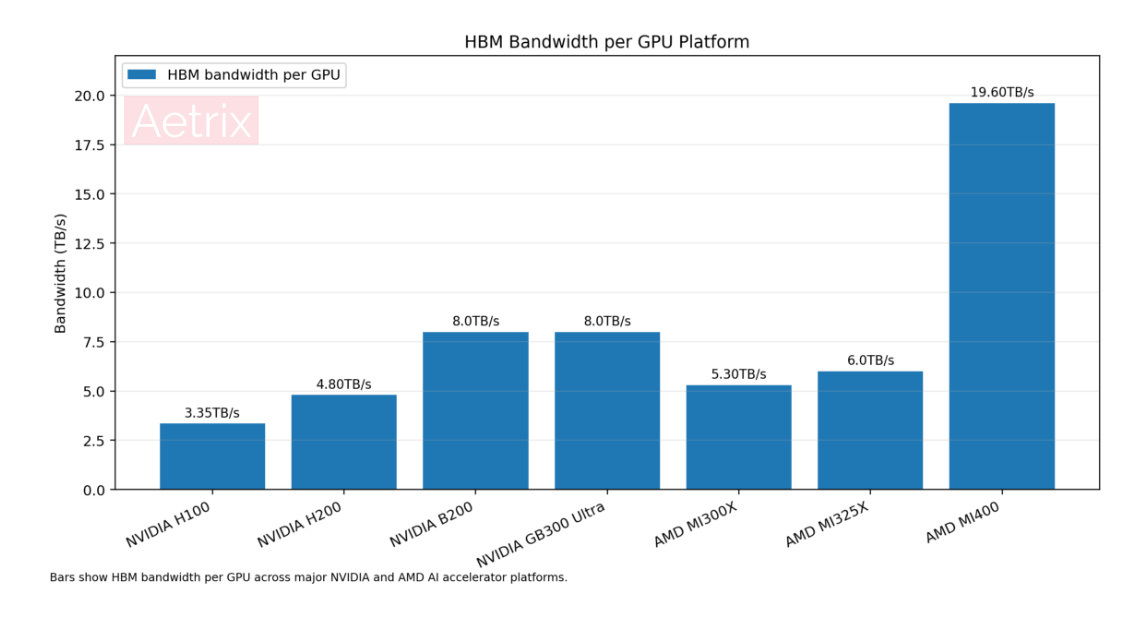
The AI accelerator roadmap is increasingly defined by memory capacity and bandwidth. The jump from H100 to H200 was not mainly about changing the GPU architecture. It was largely about adding more and faster HBM. NVIDIA describes H200 as the first GPU to offer 141GB of HBM3E at 4.8TB/s, nearly doubling capacity compared with H100 and increasing bandwidth by 1.4 times (NVIDIA H200 Product Information).
Blackwell and Blackwell Ultra continue the same direction. NVIDIA GB200 NVL72 integrates 72 Blackwell GPUs and provides 13.4TB of HBM3E with 576TB/s total GPU memory bandwidth at rack scale (NVIDIA GB200 NVL72 Specifications). GB300 NVL72 then increases Blackwell Ultra GPU memory to 288GB of HBM3E per GPU for larger reasoning and long-context inference workloads (NVIDIA GB300 NVL72 Product Information).
| GPU / Platform | HBM Type | HBM Capacity per GPU | Memory Bandwidth | Source Basis |
|---|---|---|---|---|
| NVIDIA H100 | HBM3 | 80GB | 3.35TB/s | NVIDIA platform data |
| NVIDIA H200 | HBM3E | 141GB | 4.8TB/s | NVIDIA official data |
| NVIDIA B200 | HBM3E | 192GB | 8.0TB/s | NVIDIA / platform specification data |
| NVIDIA GB300 Ultra | HBM3E | 288GB | 8.0TB/s class | NVIDIA GB300 information |
| AMD MI300X | HBM3 | 192GB | 5.3TB/s | AMD official data |
| AMD MI325X | HBM3E | 256GB | 6.0TB/s | AMD official data |
| AMD MI400 | HBM4 | 432GB estimated | 19.6TB/s estimated | Roadmap / industry estimate |

This memory growth is not cosmetic. Large language model training and inference are both limited by memory capacity, memory bandwidth and data movement efficiency. Training depends on HBM for high-throughput matrix operations and model parallelism. Inference depends on memory for model weights, KV cache, long-context processing, retrieval systems, embeddings and multi-user serving. As AI moves toward reasoning, agents and long-context workloads, memory becomes part of the performance ceiling.
HBM Moves Into the Center of DRAM Revenue
HBM was once a high-end memory category for specialized accelerators. In the AI server cycle, it has become one of the main growth engines of the DRAM industry. The data set used for this article estimates HBM revenue at roughly $25.6 billion in 2024, growing to about $38.2 billion in 2025. HBM's share of the DRAM market is estimated at around 26.5% in 2024 and 28.5% in 2025, with a potential path toward more than 35% in 2026 and above 40% by 2028.
TrendForce has also noted that HBM usage is expected to keep rising strongly in 2026, driven by B300, GB300, R100/R200, VR100/VR200, Google TPU and AWS Trainium platforms, with HBM consumption still expected to grow more than 70% annually (TrendForce HBM Consumption Forecast).
| Year | Estimated HBM Revenue | Growth / Demand Signal | Estimated HBM Share of DRAM |
|---|---|---|---|
| 2024 | ~$25.6B | +200%+ estimated | ~26.5% |
| 2025 | ~$38.2B | +49.2% estimated | ~28.5% |
| 2026 | Not specified | HBM consumption +70%+ expected | 35%+ estimated |
| 2028 | $80B+ estimated | HBM4E / HBM5 expansion | 40%+ estimated |

The pricing difference between HBM and conventional DDR5 is one reason the revenue impact is so large. The compiled data suggests HBM3E stack pricing can be several times higher than DDR5 on a per-GB basis. Even if HBM unit prices decline after capacity ramps, the total value pool can continue expanding because each new AI accelerator generation uses more HBM per device.
SK hynix Plans for a Bigger Memory Cycle
The clearest supply-side signal came at Computex 2026. SK Group Chairman Chey Tae-won said SK hynix plans to double wafer capacity over the next five years to meet AI-driven memory demand, while also warning that memory bottlenecks may continue through 2030 (Reuters, SK hynix Wafer Capacity Plan).
At the same event, NVIDIA CEO Jensen Huang visited SK hynix's booth and wrote "Please Make More" on an HBM4E wafer. The message was informal, but the supply-chain meaning was clear: NVIDIA's next AI platforms need more advanced memory than the industry can comfortably supply today.
This detail connects the demand side and the supply side in one image. NVIDIA is pushing AI platforms toward larger HBM capacity and higher bandwidth, while SK hynix is preparing a multi-year wafer capacity expansion. The two trends are part of the same AI infrastructure cycle.
| Timeframe | SK hynix Monthly Wafer Capacity | Change | Main Driver |
|---|---|---|---|
| Mid-2026 | ~550K wafers/month | Baseline | Existing DRAM capacity, including Wuxi |
| 2026H2 target | ~620K wafers/month | +13% | M15X ramp-up |
| 2030–2031 target | ~1,000K wafers/month | +82%, close to doubling | Yongin Semiconductor Cluster and long-term AI memory expansion |

This is total wafer capacity, not pure HBM capacity. Still, HBM and advanced DRAM are the strategic drivers behind the expansion. More wafer starts are necessary, but not sufficient. HBM supply also depends on TSV processing, die stacking, thermal control, testing capacity, advanced packaging and customer qualification cycles.
| Yongin Expansion Step | Expected Timing | Added Monthly Capacity | Cumulative Added Capacity |
|---|---|---|---|
| First cleanroom equipment move-in | February 2027 | +60K wafers/month | 60K wafers/month |
| Second cleanroom estimate | August 2027 | +60K wafers/month | 120K wafers/month |
| Third cleanroom estimate | February 2028 | +60K wafers/month | 180K wafers/month |
| Fourth cleanroom estimate | August 2028 | +60K wafers/month | 240K wafers/month |
| Fifth cleanroom estimate | February 2029 | +60K wafers/month | 300K wafers/month |
| Sixth cleanroom estimate | August 2029 | +60K wafers/month | 360K wafers/month |
Samsung and Micron Push Into the Next HBM Cycle
Samsung and Micron are also accelerating HBM development and packaging capacity. Samsung announced mass production of HBM4 in February 2026, using a 4nm logic base die and 6th-generation 10nm-class DRAM process, with transfer speeds of 11.7Gbps and capability up to 13Gbps (Samsung HBM4 Announcement).
Micron has also moved quickly. Its HBM4 36GB 12-high product is in high-volume production for next-generation AI platforms, with more than 11Gb/s pin speed and more than 2.8TB/s bandwidth. Micron has also shipped samples of 48GB 16-high HBM4 to customers, increasing capacity per HBM placement by 33% versus its 36GB 12-high product (Micron HBM Product Information).
Packaging capacity is now just as important as front-end DRAM wafer capacity. SK hynix announced a $3.87 billion advanced packaging facility in Indiana for next-generation HBM AI products, while Micron broke ground on a roughly $7 billion HBM advanced packaging facility in Singapore, scheduled to begin operations in 2026 with meaningful expansion in 2027 (SK hynix Indiana Advanced Packaging Facility; Micron Singapore HBM Advanced Packaging Facility).

| Supplier | Expansion / Product Focus | Timing | Strategic Meaning |
|---|---|---|---|
| SK hynix | M15X, Yongin cluster, Indiana advanced packaging | 2025–2031 | HBM leadership and long-term wafer capacity expansion |
| Samsung | HBM4 mass production, HBM4E / HBM5 roadmap | 2026 onward | Attempt to regain competitiveness in next-generation HBM |
| Micron | HBM4, 16-high HBM sampling, Singapore packaging | 2026–2027 | Rising share in AI memory and stronger packaging footprint |
Why Expansion May Not End the Shortage Quickly
The memory industry is expanding capacity, but the data does not suggest immediate oversupply. The compiled supply-demand estimates show HBM demand rising from roughly 350–400 million stacks in 2024 to more than 1.15 billion stacks by 2027. Supply is also expanding, but the gap may remain significant through 2026 and only narrow gradually after 2027.
| Year | Estimated HBM Demand | Estimated HBM Supply | Estimated Gap |
|---|---|---|---|
| 2024 | 350–400M stacks | 230–260M stacks | 30–40% shortage |
| 2025 | 500M+ stacks | 350–400M stacks | 20–30% shortage |
| 2026 | 750–850M stacks | 600–680M stacks | Still tight |
| 2027 | 1.15B+ stacks | ~1.0B stacks | 10–15% shortage |
This is why capacity doubling does not automatically mean near-term price relief. New memory fabs require years of construction, equipment installation, process qualification and yield ramp. HBM adds further complexity because it requires known-good dies, TSV processing, stacking, thermal control and high-end testing. In practice, the bottleneck can move from wafers to packaging, from packaging to test, or from HBM stacks to CoWoS-like advanced package capacity.
The Spillover Into DDR5 and RDIMM
AI memory demand is not limited to HBM. As memory suppliers allocate more advanced DRAM capacity to HBM and high-margin server products, traditional DRAM supply can tighten as well. The result is visible in DDR5, RDIMM and spot DRAM price trends.
The compiled pricing data shows 64GB RDIMM pricing rising from about $255 in 2025Q3 to about $450 in 2025Q4, with a 2026Q1 forecast near $700. DDR5 16Gb spot pricing also rose sharply in the data set, from $7.68 in September 2025 to $15.50 in November and $27.20 in December.
| Period | Product | Price | Change |
|---|---|---|---|
| 2025Q3 | 64GB RDIMM | $255 | Baseline |
| 2025Q4 | 64GB RDIMM | $450 | +76% |
| 2026Q1 forecast | 64GB RDIMM | $700 | +56% |
| September 2025 | DDR5 16Gb spot | $7.68 | Baseline |
| November 2025 | DDR5 16Gb spot | $15.50 | +102% |
| December 2025 | DDR5 16Gb spot | $27.20 | +298% |


The spillover mechanism is straightforward. AI servers consume HBM directly, but they also require large amounts of DDR5, LPDDR, NAND flash, SSDs and supporting memory interface components. At the same time, DRAM suppliers may prioritize high-margin HBM and server memory over lower-margin consumer segments. That can tighten availability for PC DRAM, consumer modules, industrial memory and embedded memory products.
CXL, CoWoS and the New Memory Layer
HBM solves the near-package bandwidth problem, but it does not solve every memory scaling problem. AI systems still need larger memory pools, lower-cost capacity tiers, faster host-device movement and more flexible memory allocation. This is where CXL, advanced packaging and high-speed interconnects become important.
CXL is designed to support coherent memory expansion, memory pooling and device-level memory sharing. Montage Technology said its CXL Memory eXpander Controller passed CXL 2.0 compliance testing and was used in tested products from major memory suppliers including Samsung and SK hynix (Montage Technology CXL Memory eXpander Controller). While HBM provides the highest bandwidth close to the GPU, CXL can help expand memory capacity at the system level.
| Technology | Role in AI Memory Architecture | 2026–2027 Direction |
|---|---|---|
| HBM3E | High-bandwidth GPU memory | Mainstream in H200, B200, GB300-class platforms |
| HBM4 | Next-generation GPU memory with higher speed and capacity | Production ramp for next AI platforms |
| HBM4E | Higher-capacity and higher-bandwidth HBM roadmap extension | Sampling and platform qualification |
| CXL | Memory expansion and pooling beyond local DRAM | Server ecosystem deployment |
| CoWoS / advanced packaging | GPU + HBM integration and high-density interconnect | Continued capacity expansion |
AI memory is becoming a layered architecture rather than a single component category: HBM for immediate accelerator bandwidth, DDR5 and LPDDR for host and CPU memory, CXL for expansion and pooling, NAND SSDs for training data and inference storage, and advanced packaging to physically connect memory to compute.
Inference Adds Another Layer of Demand
The first phase of the AI infrastructure cycle was driven by training large models. The next phase is increasingly driven by inference: AI search, copilots, agents, long-context assistants, code generation, multimodal applications and enterprise deployments. Inference does not remove memory pressure. It moves memory pressure into new forms.
Long-context inference requires KV cache. Agent workflows require user history, retrieval indexes and structured memory. Multimodal systems add image, audio and video embeddings. Enterprise AI deployments often require local data stores, vector databases and retrieval-augmented generation pipelines. Inference growth therefore increases demand for both high-speed memory and persistent storage.
| Platform / Model Group | User Scale / Deployment Type | Context Length Trend | Memory Pressure |
|---|---|---|---|
| OpenAI / GPT-class systems | Hundreds of millions of weekly users | 128K-class context | Very high, especially for KV cache and multi-user serving |
| Google Gemini-class systems | Large consumer and enterprise deployment | 1M–2M context range in high-end use cases | Very high, especially for long-context workloads |
| Anthropic Claude-class systems | Enterprise and developer adoption | 200K to 1M context range | High, especially for enterprise document processing |
| Open-source Llama ecosystem | Distributed global deployment | 128K and beyond in derivative models | Distributed memory demand across cloud, edge and private infrastructure |
| ByteDance / Doubao and Chinese AI platforms | Large daily active user bases | 128K-class context | High demand for inference serving and user data storage |
These figures should be treated as modeled estimates rather than official reported memory consumption. Still, the direction is clear: each user prompt, each context window, each retrieval operation and each generated token creates data movement inside AI infrastructure. That data movement eventually touches HBM, DRAM, cache, SSDs, memory controllers, CXL devices or networking fabric.
The Wider Component Supply Chain
The AI memory cycle benefits the big three DRAM suppliers first, but it also affects the broader memory and component ecosystem. Smaller DRAM suppliers, NAND flash vendors, memory interface IC companies, module suppliers, SSD vendors and CXL controller companies can all be pulled into the AI infrastructure supply chain.
| Company / Category | Main Product Area | AI Server Relevance |
|---|---|---|
| Nanya Technology | DRAM | Potential second-tier DRAM role as supply tightness expands |
| Winbond | Specialty DRAM | Edge AI and specialty memory applications |
| CXMT | DRAM | Longer-term China DRAM supply, but HBM ramp remains challenging |
| Kioxia / Western Digital | NAND flash | AI server SSDs and inference storage |
| Solidigm | Enterprise SSDs | High-capacity AI data storage and server SSDs |
| Montage Technology | Memory interface / CXL controllers | CXL memory expansion and server memory interface products |
| Rambus | Memory interface IP and chips | High-speed memory interface and CXL ecosystem |
| SMART Modular | Memory modules | Server memory modules and AI infrastructure configurations |
For distributors, the effect is not limited to memory parts. AI server growth also influences power ICs, BMCs, high-layer-count PCBs, connectors, capacitors, inductors, thermal materials, memory sockets, retimers, clock ICs, SSD controllers and high-speed interface components. TrendForce has already noted that AI server demand is extending lead times for multiple general server components, including PCBs, CPUs, power ICs and BMC ICs (TrendForce Server Component Lead Time Update).
Supply Chain Implications
The AI memory cycle changes how the semiconductor supply chain should be read. In older server cycles, DRAM was important but often treated as a standard commodity. In AI servers, HBM capacity, memory bandwidth and memory packaging can directly constrain GPU platform output. That gives memory suppliers stronger pricing power and deeper customer relationships with GPU vendors, hyperscalers and sovereign AI projects.
Capacity decisions are also becoming longer-term and more capital-intensive. SK hynix's plan to double wafer capacity over five years shows that memory suppliers are no longer planning only for a normal DRAM upcycle. They are planning for AI-driven structural demand. But fabs, equipment, water, electricity, cleanrooms and packaging lines take time, so the supply response cannot be immediate.
Pricing pressure can also spread from HBM to conventional DRAM. When leading suppliers allocate wafers and packaging resources toward HBM, DDR5 and RDIMM supply can tighten. That affects server OEMs, PC makers, industrial device manufacturers and distributors.
CXL and modular memory architectures may become more important in this environment. HBM is extremely fast but expensive and physically limited by package area. DDR5 is cheaper but slower. CXL can create an intermediate path by enabling memory expansion and pooling beyond local DIMM capacity. It does not replace HBM, but it can help manage system-level memory pressure.
AI infrastructure also increases demand for many non-memory components. High-current power modules, voltage regulators, high-speed connectors, signal integrity components, cooling materials, SSDs, clocking devices, interface ICs and advanced PCBs all become part of the same cycle. The memory shortage is therefore connected to the wider electronic component supply chain.
Memory Is Becoming the Constraint That Defines AI Infrastructure Growth
AI servers are changing the economics of the memory chip market. HBM is moving from a premium niche product to a major DRAM revenue engine. DDR5 and RDIMM prices are showing spillover pressure from AI demand. CXL is emerging as a system-level memory expansion technology. Advanced packaging is becoming a supply constraint. SK hynix, Samsung and Micron are all expanding, but the growth of GPU platforms, AI ASICs and inference workloads suggests that memory supply may remain tight for years.
The most memorable signal may not be a market forecast, but the message Jensen Huang wrote on an SK hynix HBM4E wafer: "Please Make More." It captured the state of the AI hardware supply chain in three words. The AI industry does not only need more GPUs. It needs more memory, more bandwidth, more packaging capacity, more CXL expansion and more supply-chain coordination.
For the semiconductor industry, this marks a new cycle. AI infrastructure is turning memory chips from supporting components into strategic assets. The companies that control HBM, DDR5, CXL memory expansion, NAND storage and advanced packaging will shape not only the memory market, but also the pace at which AI data centers can continue to scale.


 Current Transfer Ratio and Isolation Voltage Characteristics")
 Linear Regulator Dropout Voltage and Power Supply")